上一篇文章我们说到了jmeter命令行运行但是是单节点下的, jmeter底层用java开发,耗内存、cpu,如果项目要求大并发去压测服务端的话,jmeter单节点难以完成大并发的请求,这时就需要对jmeter进行分布式测试:
1:先说说分布式测试原理

处理过程:
一:调度机master启动以后,会拷贝本地的jmx文件分发到远程的slave机器上;
二:slave机器拿到脚本以后启动命令行模式去执行脚本,对于每台slave机器拿到的脚本都是一样的,所以如果jmx脚本为50个线程跑3分钟,那么实际并发就是50*3=150个线程并发跑3分钟;
三:执行时,slave会把执行获得的数据结果传给master机器,master机器会收集所有slave机器的信息并汇总,这样master机器上就存在一份所有slave机器汇总的数据结果。
注意事项:
一:我们注意到master机器启动后会拷贝jmx文件到slave机器,所以我们不需要在每台slave机器上也上传一份jmx,只需要在master机器上上传一份jmx脚本即可。
二:参数化文件:如果使用csv进行参数化,那么需要把参数文件在每台slave上拷一份且路径需要设置成一样的。
三:调度机(master)和执行机(slave)最好分开,由于master需要发送信息给slave并且会接收slave回传回来的测试数据,所以mater自身会有消耗,所以建议单独用一台机器作为master。
四:保证每台机器的jmeter版本和插件版本相同,避免造成一些意外问题。
五:分布式测试总样本数 = 线程数 * 循环次数 * 执行机总数, 样本计数逻辑为:执行机slave执行的测试脚本是由调度机master分发的,故每台执行机执行的测试脚本都是相同的,故而性能测试总样本数 = 测试脚本样本数 * 执行机总数,而测试脚本样本数为线程数 * 循环次数
2:说完了原理,现在我们来说如何做jmeter分布式测试
- 在所有需要做分布式的机器上部署java和jmeter,要求需要保证每台机器上部署的jmeter版本相同插件版本也相同,最好部署在同一路径下(这样如果有csv参数化比较方便)
部署jmeter很简单,只需从官网下载相应版本然后传到服务器上进行解压缩就可以了这里给出我的云盘地址:http://pan.baidu.com/s/1bI3r2I 密码:f5ll。
比如我部署在134.64.14.95、134.64.14.96、134.64.14.97、134.64.14.98四台机器上,每台机器部署路径为:/home/tester

- 修改slave机器bin目录下的jmeter.properties配置,我的3台slave机器为:134.64.14.96、134.64.14.97、134.64.14.98
修改3台slave机器jmeter/bin目录下的jmeter.properties中server_port端口号为机器未被占用的端口号,一般默认为1099,此处我修改为7899(可以使用默认端口或者改成其他端口,只要未被占用就行),remote_hosts为127.0.0.1不需要修改
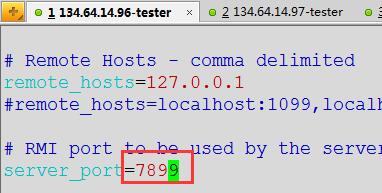
修改完成保存,我配置的3台机器为:
134.64.14.96机器(remote_hosts:127.0.0.1、server_port:7899)
134.64.14.97机器(remote_hosts:127.0.0.1、server_port:7899)
134.64.14.98机器(remote_hosts:127.0.0.1、server_port:7899)
- 完成slave机器的配置后,此时配置master机器,我的1台master机器为134.64.14.95
注意到由于master机器作为调度机本身会有一定的性能消耗所以我们配置远程执行机的时候并没有把master机器配置进去,只配置了3台执行机

修改完成保存,我配置的1台机器为:
134.64.14.95机器(remote_hosts:134.64.14.96:7899,134.64.14.97:7899,134.64.14.98:7899、server_port:注释掉不用打开)
- 完成了所有机器配置后,我们需要上传测试脚本,测试时只需要上传jmx文件到master机器即134.64.14.95机器的jmeter对应目录即可,其他执行机不需要上传jmx文件,因为master启动后会拷贝本地jmx到远程执行机上

- 现在我们来启动分布式测试,启动分布式测试分两步:
一:首先启动执行机即slave机器134.64.14.96、134.64.14.97、134.64.14.98,每台slave机器都需要执行以下命令来启动jmeter-server
命令为:./jmeter-server

二:确认3台slave执行机都启动正确完成后,在启动master机器134.64.14.95,执行如下命令开启分布式测试
命令为:./jmeter -n -t baidu_requests_results.jmx -r -l baidu_requests_results.jtl
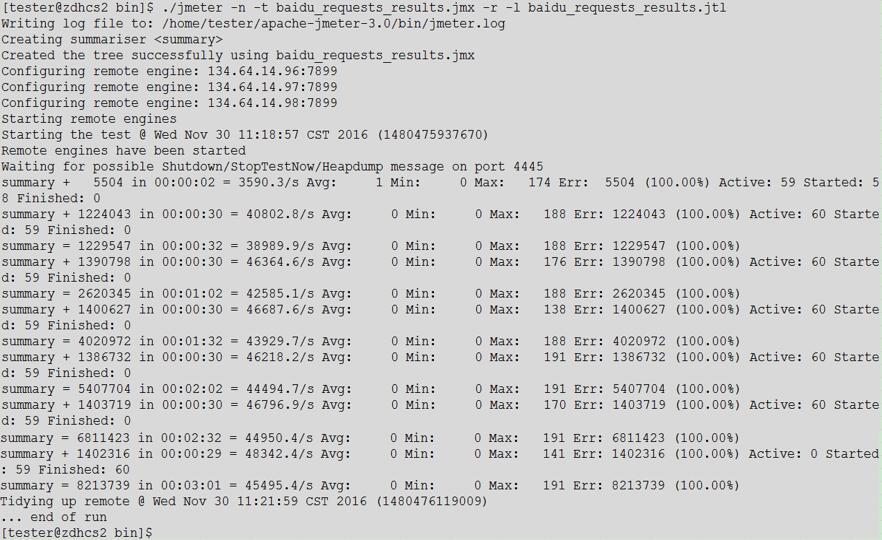
3:测试命令说明
./jmeter -n -t baidu_requests_results.jmx -r -l baidu_requests_results.jtl
4:测试结果说明
注意到上面控制台打印的信息中